
The Clerical Skills Test is a targeted assessment created to measure a candidate’s proficiency in clerical and administrative tasks. With six focused sub-tests, it offers a thorough evaluation ideal for positions such as clerks, receptionists, secretaries, and other administrative roles.
This test provides a clear and accurate assessment of critical clerical skills, streamlining the hiring process by helping you identify candidates best suited for administrative responsibilities. Featuring instant scoring and detailed reports, the Clerical Skills Test ensures quick, confident, and informed hiring decisions.
Test properties
Type of test: Skills test
Useful for: Predicting job performance in administrative jobs
Estimated time: 30 – 35 minutes
Languages: English
Mode of Administration: Online
Download Resources
What the sub-tests measure
Alphabetic and numerical filing (time limit: 7 minutes)
This test assesses a candidate’s ability to apply common rules of alphabetical and numerical filing. It consists of 20 items.
Attention to detail (time limit: 3 minutes)
This sub-test measures how detail-oriented a candidate is while working under a strict time limit. Every correct answer increases the candidate’s score by 1, while every wrong answer decreases it by 1, encouraging quick yet precise work.
Data checking (time limit: 5 minutes)
Candidates are presented with tables of information to check against each other. This sub-test emphasizes speed without sacrificing accuracy.
Workload / Concentration (time limit: 2 minutes)
Candidates must quickly read, analyze a short sentence, and answer a related question. Speed and precision are key, with scoring based on the accuracy of responses.
Basic verbal skills (time limit: 10 minutes)
This sub-test comprises 30 items focused on vocabulary, grammar, and spelling, indicating a candidate’s proficiency in processing basic verbal information.
Basic math skills (time limit: 5 minutes)
Candidates face basic mathematical calculations including addition, subtraction, multiplication, division, and percentages. The focus is on solving as many problems as accurately as possible within the time limit.
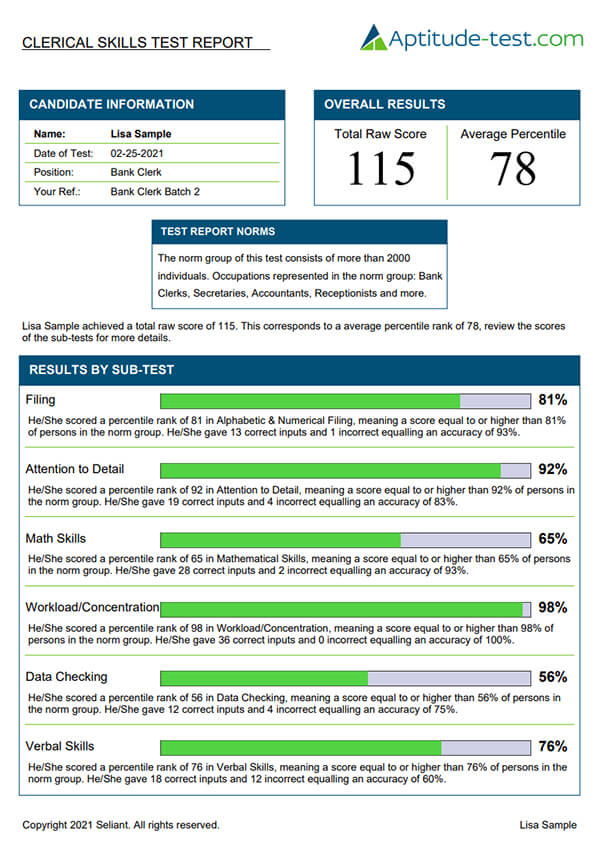
Detailed Test Report
For every candidate completing the Clerical Skills Test, you will be able to download or print a detailed test report. The candidate’s results are compared to norm groups to determine their percentile population score. If a candidate scores 70, they performed as well or better than 70 percent of the 2,000 people who were part of our 2014 test survey. The candidate receives a percentile population score for each of the six sub-tests of the Clerical Skills Test.
Click here to view a sample test report.

Prices
Simple and affordable
Account setup fee
(one time only)
$50
Price per test credit
(same for all tests)
$6
No subscription fees
Instant access
Credits do not expire
Clerical Skills Test
Test Sample
Contact us to request a full-length sample of the Clerical Skills Test.
Unlock the potential of your hiring process

2000+
Companies served
50,000+
Candidates assessed
100,000+
Assessments conducted
12+
Years experience